Data analysis
Data analysis takes on many names and may forms. In the context of this resource data analysis is the use of code or tools to process the data we have collected, cleaned and formated for use. This is where we use our data to inform our decision making, identify themes and gaps in the research and find evidence to support findings.
Methods for analysis
Once the text is cleaned and formatted it can be computationally processed using a number of different methods, depending the analysis you want to undertake. Explore some of popular the methods below.
Natural language processing (NLP) techniques
Natural language processing (NLP) is the branch of artificial intelligence (AI) technology to train a computer to understand, process, and generate language. Search engines, machine translation services, and voice assistants are all powered by the technology. Source: Bell & Olavsrud, 2021
The following NLP tasks break down text into analysable parts:
| NLP method | Description | Example |
| Tokenization | Splits the text into sentences and sentences into words; changes to lowercase and removes punctuation. | This is creates a ‘bag of words’ for analysis |
| Stop word removal | Uses standard language stop word dictionaries which can be amended. | removes words such as “the”, “and”, “it”, “so”, “this”, “page”, “of”…. |
| Lemmatization | Third person words are changed to first person and verbs in past and future tenses are change into present. | Alters change, changing, changes, changed… to change |
| Word stemming | Words are reduced to their root form. | Changes victorious, victories, victory… to victor |
| Special characters removed | Characters that cannot be understood are removed. | * @ # ! » |
| Part-of-speech tagging | Categorises words in a text in correspondence with a particular part of speech. | Her (pronoun) hat (noun) is (verb) grey (adjective). |
| Shallow parsing | Chunks phrases from unstructured text. | Identifies sentences, verb phrases, noun phrases. |
| Syntactic parsing | Finds structural relationships between words in a sentence. | Can for example identify a noun phrase as being formed by a determiner, followed by an adjective, followed by a noun. |
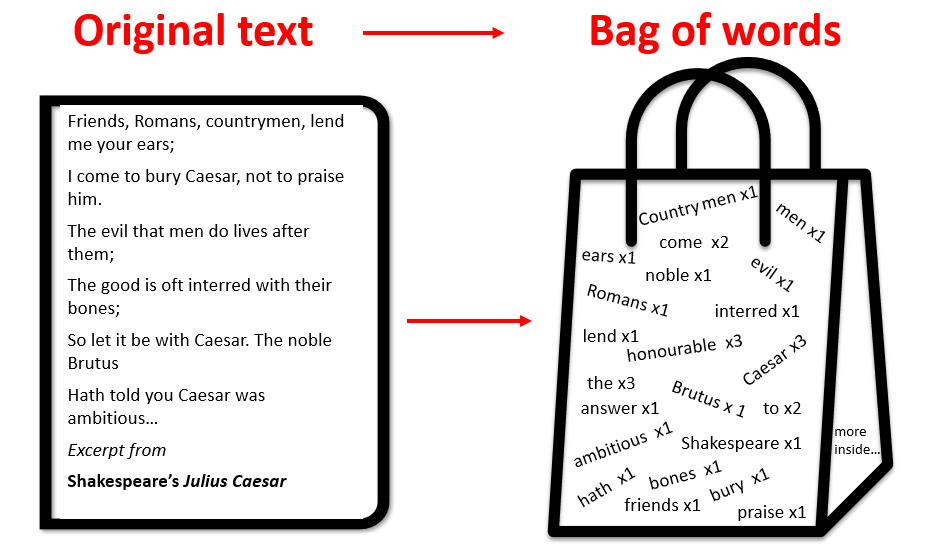
Machine learning
Machine learning is a branch of AI and a process of teaching a computer system to recognise patterns in text without explicit human programming. Machine learning can be either unsupervised (with minimal human intervention) or supervised (with more human intervention). Explore machine learning at Zdnet.com. Analysis using Machine learning includes topic modelling, and Naive Bayes Classification, which are detailed below.
Common computational analysis tasks
Explore some common computational text analysis methods.
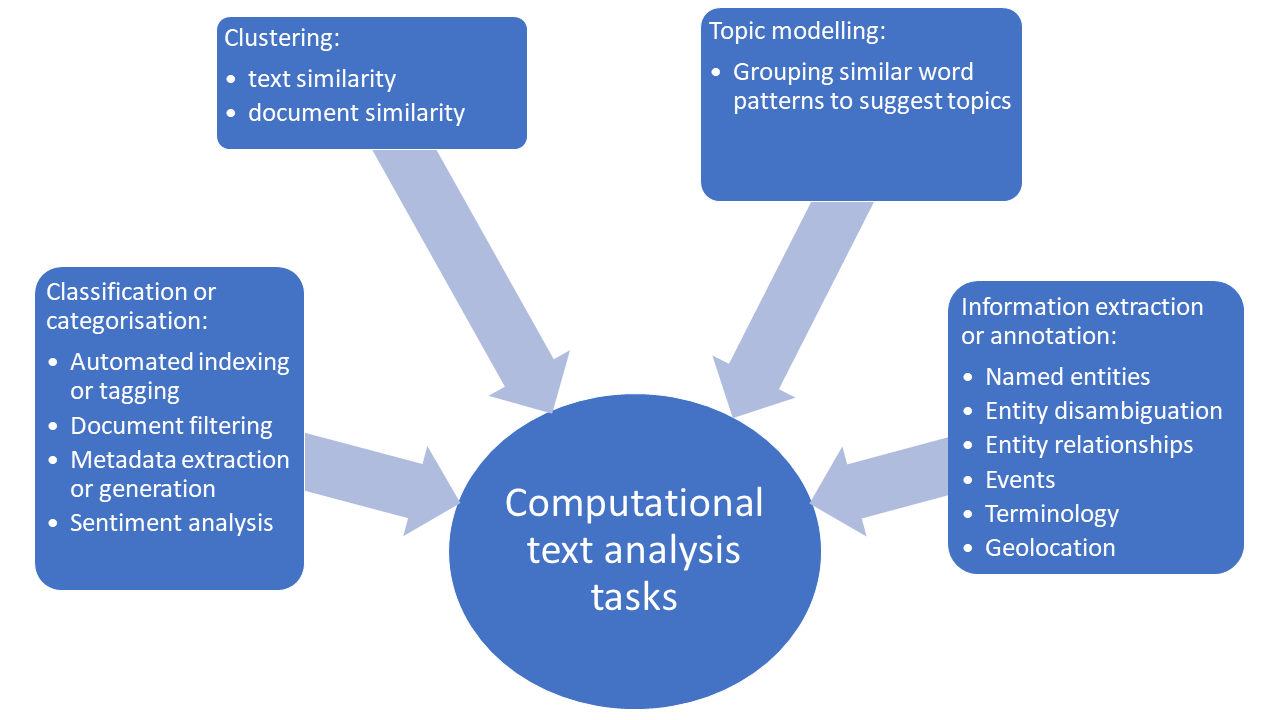
Text pattern analysis
| Linguistic patterns | such as word frequency analysis is useful for historical exploration of language as well as topic identification |
| Collocation | identifies words commonly appearing near each other |
| Concordance | shows the context of (the words around) a given word or set of words |
| N-grams | finds common two-, three-, etc. word phrases see Google books Ngram viewer |
| Dictionary tagging | locates a specific set of words in texts |
Analysing one or a number of texts of interest
| Method | Description | Example |
| Topic modeling | Unsupervised machine learning to identify groups of terms that may be representative of a given topic, uncovering hidden themes. | Topic mapping for a literature review |
| Document classification | Such as Naive Bayes Classfication uses machine learning to classify documents based on information in the text | Used in Sentiment analysis and literature reviews. |
| Sentiment analysis | Used to determine whether text is positive, negative, or neutral. Used in research to see public sentiment, opinions, or emotions about products, ideas or policy, and can undertaken via NLP or machine learning. | Tweet Sentiment Visualization App from NC State University. |
| Network analysis | Analysis of social or other structures comprising variables or actors (represented by nodes), and the relationships (edges) between the nodes | Network Analysis 101 |
| Named entity recognition | Generates a list of people, places, dates, times etc. | Booking.com user experience analysis |
| Stylometry | Statistical method of studying a linguistic style. | Used in forensic, attribution and genre analysis. |
Learn more about these methods from:
- Australian Text Analytics Platform Methods Guide
- An Introduction to Text Mining: Research Design, Data Collection, and Analysis ebook
- Prof. Miriam Possner’s Topic Modelling online tutorials
- Demystifying Networks an introduction for HASS scholars.
- Introduction to Sentiment analysis fun and informative video.
- Article on comparison of machine learning methods for text-based sentiment analysis
- Article by Berger et al. on text analysis methods used in Marketing
After applying these compuational processing and analysis models and methods, the data will be ready for the most important and interesting stage, your analysis and interpretation of the results.
Analysis tools
- NVivo : performs cluster analysis, phrase nets, tag clouds, and sentiment analysis.
- Leximancer : performs network analysis, topic modeling, sentiment analysis, and named entity recognition.
Login and installation are required for both. Training is available for Griffith researchers via Researcher Education & Development.
The virtual research environments below have been developed to support digital text scholarship.
- JSTOR text mining support : for metadata, n-grams, and word counts for most articles and book chapters, and for all research reports and pamphlets available via Griffith University’s subscription to JSTOR. Login required.
- Gale Digital Scholar Lab : for document clustering, named entity recognition, Ngrams, Parts of Speech, Sentiment Analysis, Topic Modelling all available via Griffith University’s subscription. The lab is designed to use the Gale Primary Source archives, but you can use the analysis tools with your own data. Learn about it and Gale Primary Sources here. Includes online tutorials. Login required.
- Hathi Trust Research Center Analytics : supports large-scale computational analysis of the digital library works to facilitate non-profit and educational research. Individual researchers can sign up for free with their Griffith email and use out of copyright materials and analysis tools.
- Proquest TDM Studio : create an account with your university email address. Undertake geographic analysis, topic modelling or sentiment analysis of Proquest’s collection of newspapers, dissertations and theses.
The tools listed below enable users to undertake text analysis without the need to learn to code. The majority of the tools are based on Python or R codes. You can use these tools for simple or exploratory data analysis and some visulations. Some tools are downloadable to your computer, others are web interfaces, each with their own benefits and limitations.
| Advantages | Disadvantages |
| Easier to learn than coding, good for high level analysis | Can be inflexible, may not be good for deeper analysis, web based tools may not approprate for using with identifiable data. |
- Voyant Tools web based online tool for frequency, distribution and collocation of terms, keywords in context, term clusters and more.
- Sentiment Analyzer web based tool for analysing one source at a time.
- Topic Modelling toola GUI for MALLET modelling code.
- Cytoscape software platform for visualizing complex networks.
- Stanford Named Entity Recognizer (NER) for person, organisation and location recognition.
- WordHoard web application for the close reading and scholarly analysis of deeply tagged texts, from Northwestern University.
- WORDij Semantic Network Tools is downloadable software for natural language processing. It can process unstructured text from sources such as social media, news, speeches, focus groups, interviews, email, and web sites.
- CLAWS part of speech tagger for corpus annotation for English text, developed by UCREL at Lancaster University.
Try this activity using Voyant tools. Look at the results, think how you might use it for analysis and the limitations of the tool.
- R & R Studio : network analysis, topic modeling, classification/clustering, named entity recognition, sentiment analysis
- Python : network analysis, topic modeling, classification/clustering, named entity recognition, sentiment analysis
Coding tutorials for text mining and analysis
- Beginner R & Python workshops are available from Griffith’s eResearch services throughout the year.
- Constellate tutorials a series of lessons to help you learn about programming in Python, text analysis, and the Constellate platform for JSTOR.
- Programming Historian novice-friendly, peer-reviewed tutorials to help humanists learn a wide range of digital tools, techniques, and workflows. These include lesons in R and Python.
- GLAM Workbench tutorials learn how to use the GLAM Workbench, Jupyter Notebook and Python to extract and analyse data from Australia’s galleries libraries, archives and museums.
- Top 5 Unknown Sentiment Analysis Projects On Github To Help You Through Your NLP Projects
- Language Technology and Data Analysis Laboratory (LADAL) Tutorials provides online text analysis tutorials in R.
Note: Refer to software used for your research in methods notes. Attribute software developers by citation e.g.
Sinclair, Stéfan and Geoffrey Rockwell, 2016. Voyant Tools. Web. http://voyant-tools.org/.