Prepare and format
Preparing and formating your data makes it consistent and machine readable for analysis. This process differs depending on the types and formats of files you are working with. For full functional analysis your corpus documents will need to all be in the same format. This section will show the processes and tools available to help create your analysable corpus.
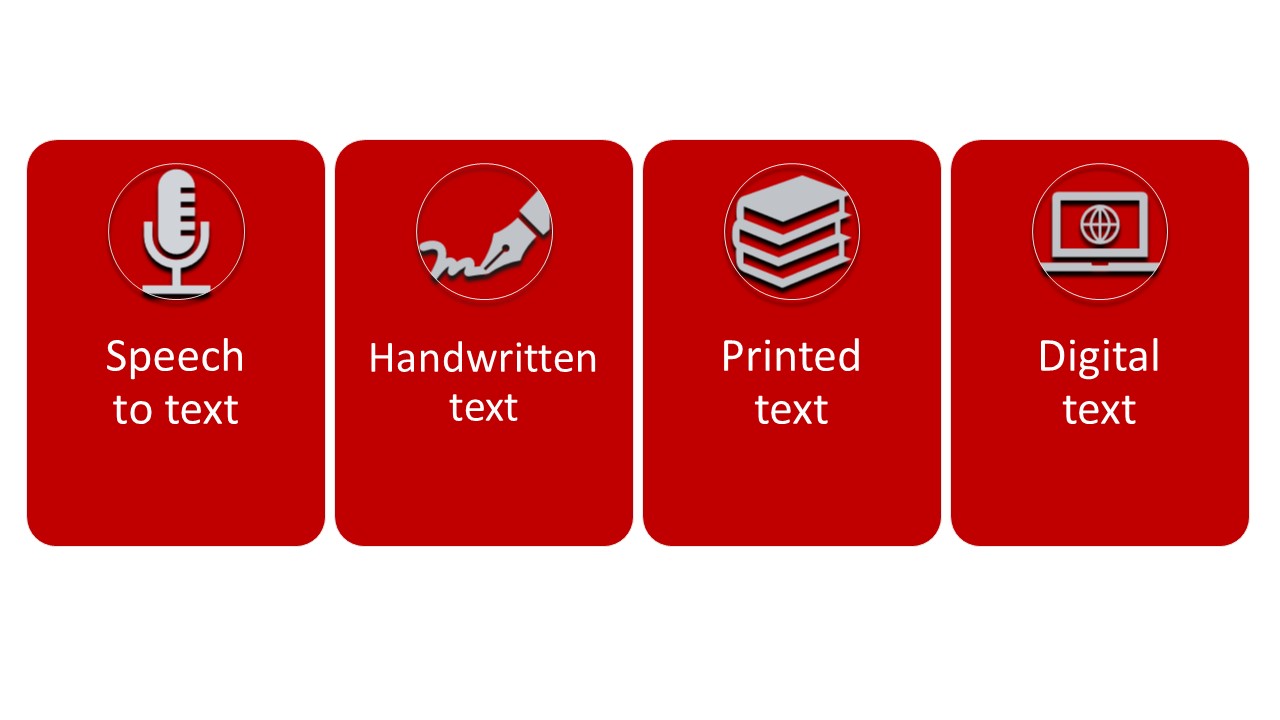
Preparation steps
There can be a number of steps to prepare, clean, then format text data depending on its type.
Interview data may be in audio or video format and require transcription. Correspondence may be handwritten on paper or in a digital format as a scanned image.
Let’s explore the different formats and preparation steps below.
Speech to text : this type of data can include audio or video recordings of surveys, focus groups, interviews, or observation videos.
Handwritten text : can include personal letters, official correspondence, ships logs, diaries, ledgers, orginal manuscripts and drafts, scientific notes, annotations, field books, recipes, survey responses .
Printed (or typed) text : includes typed versions of the handwritten text above, or books, journals, news articles, legislations, government reports, unpublished papers, official records, brochures, menus, and other primary source materials.
Digital text : includes digital versions of printed text, or content in databases, digitised collections of published or primary sources, unpublished works, your own digital documents, webpage and social media content, language corpora, interview transcripts and survey results.
Formatting text data : There is a variety of tools we can use to reformat our text data. For many materials we can simply use the ‘save as’ functions in MSword to change .doc or .rtf files to .txt and similarly we can reformat .xls files to .txt or .csv in excel. Where this is not an option we can use tools like Pandoc to easily change materail formats. we will explore other tools and process thoughout the guide.
Speech to text : manually transcribe or autogenerate the audio content and convert to .txt file format.
Handwritten text : transcribe manually or via an automated processes and convert to .txt file format.
Printed text : transcribe or digitise via a scanner then process into text via Optical Character Recognition (OCR).
Digital text : extract from databases, files, websites and reformat files to .txt file format if required.
Tools to prepare text data
These tools are featured on the next page which focuses on AV preparation.
- Transkribus handwriting recognition tool. Free to use for manual transcription and 500 credits provided to use AI models for automated transcription of different types of handwriting. Research candidates can apply for further credits.
The video below shows how to download and use Transkribus.
- Google Vision AI
- MSWord, google docs or equivalent : for manual transcription without structure or metadata capture.
- High quality scanner with OCR functionality (or OCR processing after scanning).
- Digital Camera, followed by OCR processing.
- gImageReader (students) open source OCR processor for pdfs and images of text.
Watch this video on how to install and use gImageReader to convert an image to text. In this example both Korean and English language in a pdf file are tested for conversion to text.
Other tools to assist in transcription of images to text
- Adobe Acrobat Pro DC (staff) OCR recognition.
- OpenRefine to create structure from text. Explore how to use OpenRefine with unstructured text in this Programming Historian tutorial.
- DigiVol for structured text.
- Google Docs can perform OCR on uploaded images and PDFs.
No preparation tool, including those above will create perfect text.
Errors will be generated in the transcription or conversion processes. You may need to manually review and clean the text, correcting OCR (Optical character recognition) of scanned images of pages, mis-interpretation of spoken words, and other transcription errors.
Programs such as Python can automate some cleaning processes. Read about this at machinelearningmastery.com. Some analysis programs such as Voyant tools will also clean text. More on this in the next lesson.
Unstructured vs structured text and machine readibility
Humans understand that language, and the text that represents it, is highly complex and full of structure. However text is often described as unstructured, when it does not fit easily into a database, or is not easily processed by a computer. In the context of processing text with a computer:
- Unstructured text may include text from narratives (books, articles etc.), interviews, survey responses with free text and more.
- Structured text can include metadata from GLAM catalogues or finding aides, text in structured databases, possibly spreadsheets, even old ledgers and logbooks.
All text documents, structured and unstructured, need to be formatted for machine readability by software programs or code. Let’s look at the different formats.
.txt: is the best format for unstructured text as it is non-proprietary & used in all text analysis tools. Unstructured text in file formats such as.doc,.docx,.rtf(rich text format) can be exported as.txtvia Microsoft Word..csv: is the best format for structured text data in spreadsheets and can be read by tools such as Nvivo. Use Microsoft Excel to convert file formats such as.xml,JSON,.htmlinto.csv.or.txtdelimited text file, in which atabseparates each field of text..pdf: that has been OCR processed is accepted by some analysis tools. For older texts you might need to transcribe the text or clean the data as the .pdf may be an image of a scanned document.
Prosecution Project researchers worked with a team of eResearch specialists and database and web designers to develop a structured database managed through a secure web portal. With the support of volunteers, they undertook massive digitisation, transcription and indexing work resulting in a longitudinal database of criminal prosecutions never before available in Australia. They also recognized the potential of enriching the data via links to the sources used such as newspaper articles in National Library of Australia TROVE database.
Read more about the project at: Finnane, M., & Piper, A. (2016). The Prosecution Project: Understanding the Changing Criminal Trial Through Digital Tools. Law and History Review, 34(4), 873-891. doi:10.1017/S0738248016000316
Next up: transcribing and annotating audio and video.